IFC File Data Extraction Made Easy with Streamlit
I had quite a large project in Tekla Structures where I had to export to Excel amounts of details so they could be ordered. The project had many revisions and I didn't want to recheck everything all the time. I created a Python project with a Streamlit library and used exported data from Tekla Structures as an IFC file. With simple drag and drop, I had the necessary amount list and additional automatic checks to easily track project material amounts. My script was created for a specific project with specific data, so I am not sharing all the stuff from my project, but I created quite a simple example that can work as a template and you can adjust it to your project needs.
You can see the whole project on GitHub by clicking here.
You can find a file named “IFC_4_CUBES.ifc” in project examples on GitHub. It is created to confirm everything works. Inside IFC there are four cubes made from three different types (beam, column, and two plates) and all are stretched out so they are 1x1x1 meter cubes:

To examine IFC data, cubes are made with different classes, prefixes, and other information that we will try to extract.
We are going to do two things — first, get all parts from IFC to the panda's data frame, and second, let's create an additional data frame that will count unique details within the same column together.
To make the project look good and you won't need to generate data in folders and other messy stuff, we will use Pytohns Streamlit library which allows you to make web pages with Python code.
You will need to install three Python libraries:
streamlit==1.39.0
ifcopenshell==0.8.0
pandas==2.2.2When libraries are installed you can create a new app.py file and import the necessary libraries:
import ifcopenshell.util.element as Element
import streamlit as st
import pandas as pd
import ifcopenshell
import tempfile
# add this line so streamlit has wide layout
st.set_page_config(layout="wide")Before creating the main run function, let's create some helper functions.
The first function that does most of the work — gets all data from IFC. It goes through each IFC file line and retrieves the information you ask for. I have skipped a few lines which was not useful info. I have very detailed information about the IFC file I am working with, so possibly I have missed some information that could be in your IFC file.
def get_objects_data_by_class(file: ifcopenshell.file, class_type: str):
def process_property_sets(psets, pset_attributes):
for pset_name, pset_data in psets.items():
pset_attributes.update(
f"{pset_name}.{prop_name}" for prop_name in pset_data
)
return pset_attributes
objects = file.by_type(class_type)
objects_data = []
pset_attributes = set()
for object in objects:
pset_attributes = process_property_sets(
Element.get_psets(object, qtos_only=True), pset_attributes
)
pset_attributes = process_property_sets(
Element.get_psets(object, psets_only=True), pset_attributes
)
objects_data.append(
{
"GlobalId": object.GlobalId,
"Class": object.is_a(),
"Name": object.Name,
"Tag": object.Tag,
"Type": getattr(Element.get_type(object), "Name", ""),
"QuantitySets": Element.get_psets(object, qtos_only=True),
"PropertySets": Element.get_psets(object, psets_only=True),
}
)
return objects_data, list(pset_attributes)Now I can use information from this function to create a pandas data frame with all parts in the IFC model. We will need one additional helper function to get attribute values.
def get_attribute_value(object_data, attribute):
if "." not in attribute:
return object_data.get(attribute)
pset_name, prop_name = attribute.split(".", 1)
for set_type in ("PropertySets", "QuantitySets"):
if pset := object_data.get(set_type, {}).get(pset_name):
return pset.get(prop_name)
return None
def create_pandas_dataframe(data, pset_attributes):
attributes = ["GlobalId", "Class", "Name", "Type"] + pset_attributes
return pd.DataFrame(
[
[get_attribute_value(obj_data, attr) for attr in attributes]
for obj_data in data
],
columns=attributes,
)We will need one more function for filtering, but I will explain it a bit later with the help of screenshots, for now, add it to the project.
def sidebar_opt(column_names: list):
ignore_columns = []
st.sidebar.divider()
chechk_all = st.sidebar.checkbox("Check all boxes", value=True)
st.sidebar.divider()
for col_name in column_names:
if not st.sidebar.checkbox(col_name, value=chechk_all):
ignore_columns.append(col_name)
return ignore_columnsIn my project I had more stuff going on, so I wrapped all data frame processing stuff in one function, but if you want, you can add this next function logic inside the run function:
def process_df(ifc):
data, pset_attributes = get_objects_data_by_class(ifc, "IfcBuildingElement")
df = create_pandas_dataframe(data, pset_attributes)
return df.drop(columns=sidebar_opt(df.columns)).reset_index(drop=True)Finally, run the function to put it all together. We will have a file uploader and when the file is added it will extract the part list from the uploaded IFC file. It will also check if the uploaded file is an IFC file.
def run():
st.title("Exported IFC parts to excel")
st.divider()
uploaded_file = st.file_uploader(
"Upload exported ifc from tekla",
type=["ifc"],
)
if uploaded_file is not None:
if uploaded_file.name.endswith(".ifc"):
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
tmp_file.write(uploaded_file.getbuffer())
tmp_file_path = tmp_file.name
with st.spinner("Reading the IFC file..."):
exported_ifc = ifcopenshell.open(tmp_file_path)
st.success("IFC file loaded successfully!")
# --- IFC DATA ---
st.divider()
clean_df = process_df(exported_ifc)
st.header("IFC data")
st.dataframe(clean_df)
st.divider()
else:
st.error(
"The uploaded file is not an IFC file. Please upload a file with .ifc extension."
)
st.stop()
if __name__ == "__main__":
run()Now you need a terminal and in the terminal navigate to the folder with “app.py” (if you are currently not there). Then type the command:
streamlit run app.pyThis will start running the project in your main browser (I have not tested it in different browsers, but it works without issues in Chrome). If you running the Streamlit project for the first time you will see a message in the terminal to add your email, it is not necessary, just hit enter.
Info in your terminal should look something like this:

If it did not open automatically in your browser or you want to use a different browser you can use the local URL address. In the browser it must look like this:

If you have your own IFC you can try it, but for this example, I will use the IFC file that I described in the beginning (with four cubes). After uploading the IFC file you should see the table of data:
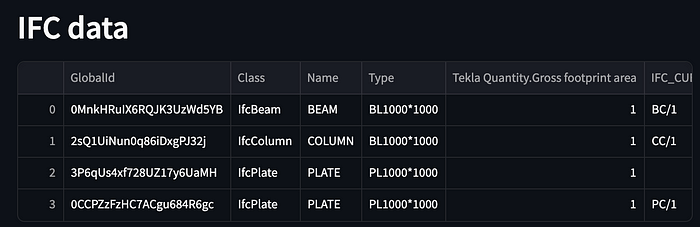
You can scroll to the right side to see all the information that will be quite a lot and you don't need it all, so here comes that sidebar_opt() function. As you can see on the left side of the screen you now should have a sidebar that looks like this:
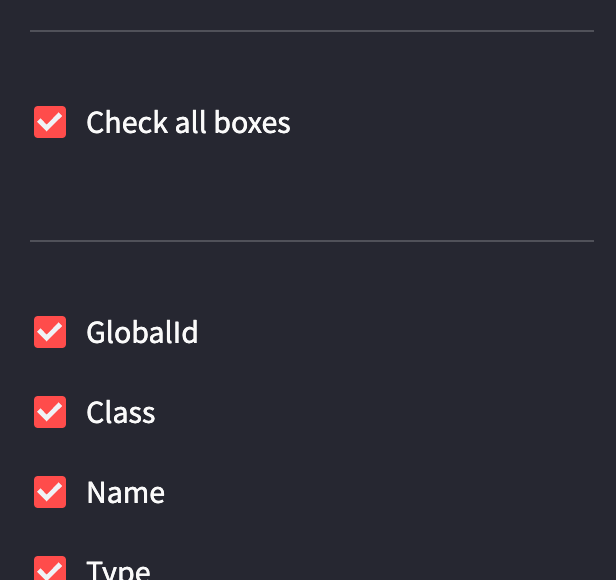
On top “Check all boxes” will check or uncheck all boxes below, so you don't have to do them one by one. The checkboxes below contain all column names from the IFC data table. So, for example, if you need a table with just two columns “Class” and “Name”, you can uncheck all checkboxes and check back only “Class” and “Name”. Your new table will look like this:

To download the table we need to create a function that will create a temp download file and add it to the download button.
def generate_excel_download_link(df: pd.DataFrame, btn_name: str):
with tempfile.NamedTemporaryFile(delete=False, suffix=".xlsx") as tmp_file:
df.to_excel(tmp_file.name, index=False, engine="openpyxl")
tmp_file_path = tmp_file.name
with open(tmp_file_path, "rb") as file:
btn = st.download_button(
label=btn_name,
data=file,
file_name="ifc_data.xlsx",
mime="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet",
)
return btnAdd button to run function below table.
def run():
...
# --- IFC DATA ---
st.divider()
clean_df = process_df(exported_ifc)
st.header("IFC data")
st.dataframe(clean_df)
# Downlaod button
generate_excel_download_link(clean_df, "Download data as Excel")
st.divider()
...The result should look like this:

We could finish here, but I also want to show how easily you can now manipulate data and get all that is important to you. As you can see every line in the table is one part from the IFC file, but let's say you need to count together details with the same part number. In the provided IFC file it is easy to count parts because there are only four cubes, but what if there were thousands of them? Let's get info about part position marks. For example, part positions are in column “IFC_CUBE.PART_POS”, but I don't want to hard code it. Instead, I want to create select options so I can choose which column to use. First, we can create a function that will count unique data together.
def create_unique_count_df(dataframe: pd.DataFrame, column_name: str):
value_counts = dataframe[column_name].value_counts().reset_index()
value_counts.columns = [column_name, "Count"]
return value_countsWe can update the run function as follows:
def run():
st.title("Exported IFC parts to excel")
st.divider()
uploaded_file = st.file_uploader(
"Upload exported ifc from tekla",
type=["ifc"],
)
if uploaded_file is not None:
if uploaded_file.name.endswith(".ifc"):
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
tmp_file.write(uploaded_file.getbuffer())
tmp_file_path = tmp_file.name
with st.spinner("Reading the IFC file..."):
exported_ifc = ifcopenshell.open(tmp_file_path)
st.success("IFC file loaded successfully!")
# --- IFC DATA ---
st.divider()
clean_df = process_df(exported_ifc)
st.header("IFC data")
st.dataframe(clean_df)
generate_excel_download_link(clean_df, "Download data as Excel")
# --- COUNT DETAILS ---
st.divider()
st.header("Count of details")
count_data_column_name = st.selectbox(
"Choose a column to count", clean_df.columns
)
if len(clean_df.columns) == 0:
st.warning("Choose column to count")
st.stop()
count_of_details = create_unique_count_df(clean_df, count_data_column_name)
st.dataframe(count_of_details)
generate_excel_download_link(count_of_details, "Download count as Excel")
st.divider()
else:
st.error(
"The uploaded file is not an IFC file. Please upload a file with .ifc extension."
)
st.stop()I am using the Streamlits “selectbox” widget and it will have all column names in it (that are checked in the sidebar) and now I can choose which column data needs to be counted together. As I mentioned I need to count together the column “IFC_CUBE.PART_POS”. I choose this column and the final result looks like this:
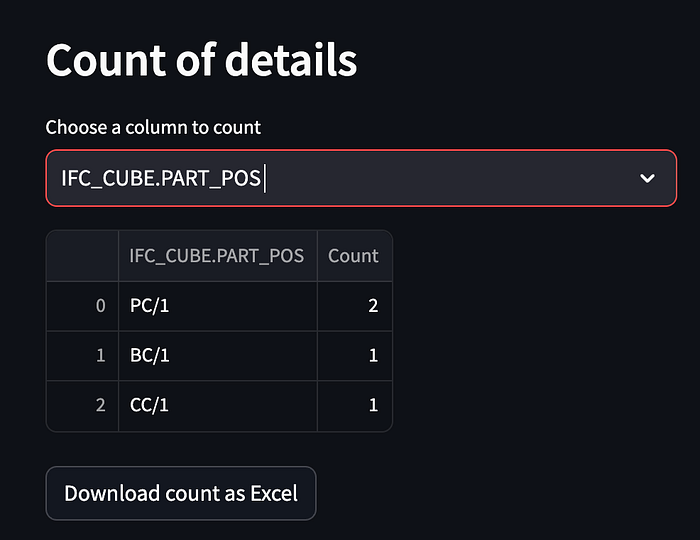
As you can see in the image at the beginning of this tutorial there were two pieces PC/1, one piece BC/1, and one piece CC/1. Similarly to this, you can create different functions that can do other stuff to your data.
As I am working quite a lot with Tekla Structures I did not try this with different IFC models from other 3D modeling software, if you have issues you can share the IFC file and in my spare time I can check if there are workarounds.
You can see the whole project on GitHub by clicking here.
